
Introduction: The building blocks of AI
Artificial Intelligence (AI) has rapidly transformed various industries, from healthcare to project management. At its core, AI relies on a set of fundamental techniques that enable machines to learn, reason, and create. Understanding these techniques is crucial for anyone looking to harness the power of AI in practical applications. This article explores four key AI techniques: regression, classification, clustering, and generative AI, providing clear explanations, practical use cases, and examples.
Generative AI: Creating a new content
What is generative AI? Definition and purpose
Generative AI refers to models that can create new content, such as images, text, and music. Unlike traditional AI models that analyze existing data, generative AI generates new data that resembles the training data. For example, it can be used to create realistic images of people who don't exist.
Types of generative models: diffusion, transformers
Generative models include diffusion models and transformers. Diffusion models gradually add noise to data and then reverse the process to generate new data. Transformers use attention mechanisms to capture long-range dependencies in data. These models offer different approaches to generating new content, each suited for specific types of data.
Use cases:
- Image generation, text generation, and music composition are common applications of generative AI. These models can create realistic images, generate coherent text, and compose original music.
- Healthcare: Taxonomy standardization and doctor’s notes analysis are valuable applications of generative AI. By analyzing medical texts, generative models can standardize medical terminology and extract relevant information from doctor’s notes.
- SoW generation: Creating project descriptions or initial drafts of SoW sections is a practical application of generative AI. By analyzing past project documents, generative models can generate new content for SoWs. To learn more about how we simplify the creation of Statements of Work (SoW) with AI, check out our detailed guide here.
While generative AI is powerful, it’s not always the most cost-effective or necessary solution. For businesses with budget constraints or structured data needs, more traditional techniques like regression, classification, and clustering can offer highly efficient and practical alternatives.
Regression: Predicting continuous values
What is regression? Definition and purpose
Regression is a statistical technique used to model the relationship between variables, allowing us to predict continuous values. In simple terms, it helps us understand how a change in one variable affects another, enabling us to make informed predictions. For instance, we can use regression to predict house prices based on factors like size and location.
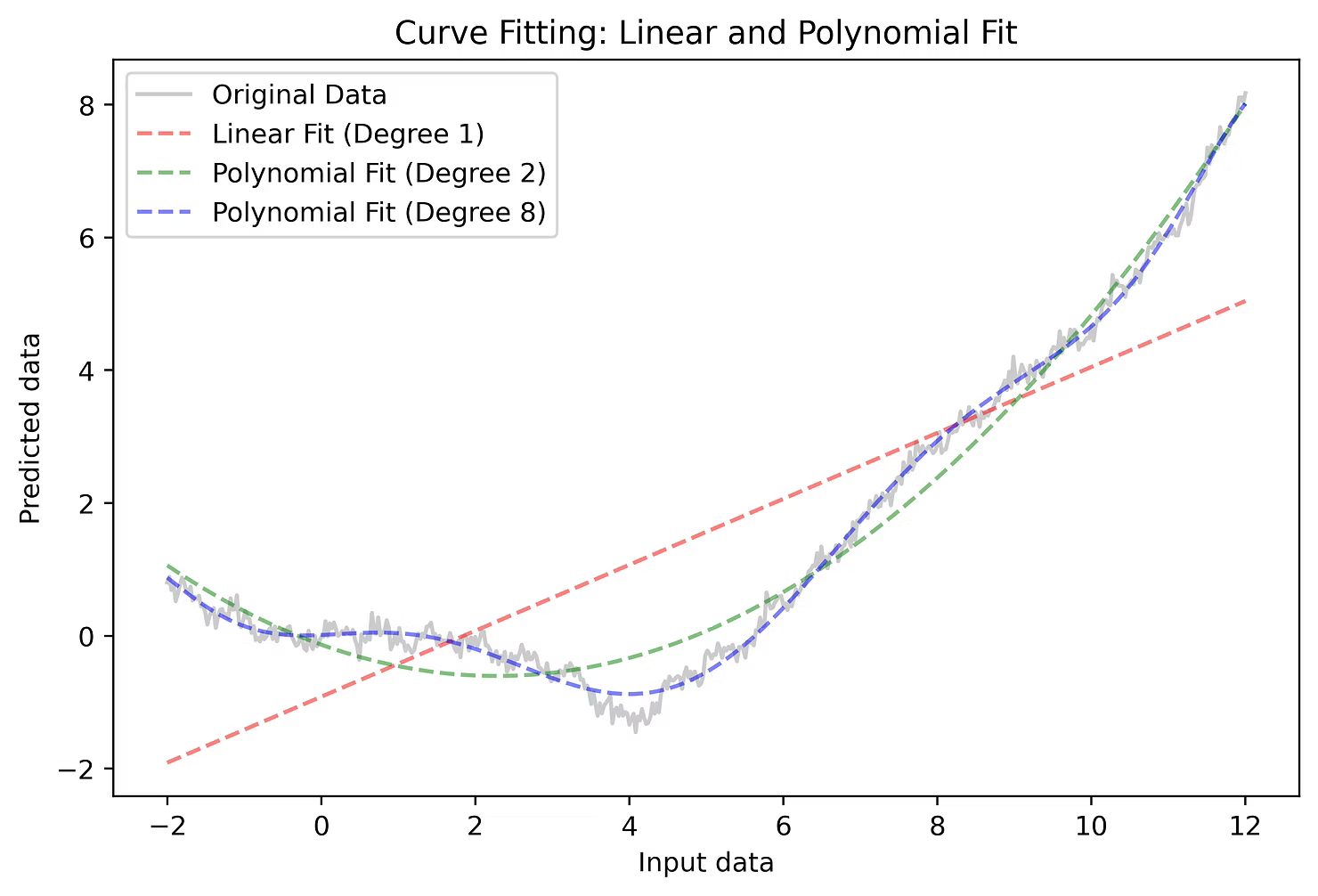
Types of regression: Linear, polynomial, and beyond
Regression models come in various forms, each suited for different types of data and relationships. Linear regression is the simplest, modeling a straight-line relationship between variables. Polynomial regression handles more complex, curved relationships. Neural networks, a more advanced form, can capture highly intricate patterns in data. These diverse techniques provide flexibility in addressing a wide range of prediction problems.
Use cases:
Stock price prediction and sales forecasting are common applications of regression. These techniques allow businesses to anticipate market trends and make informed decisions about investments and inventory.
Other examples:
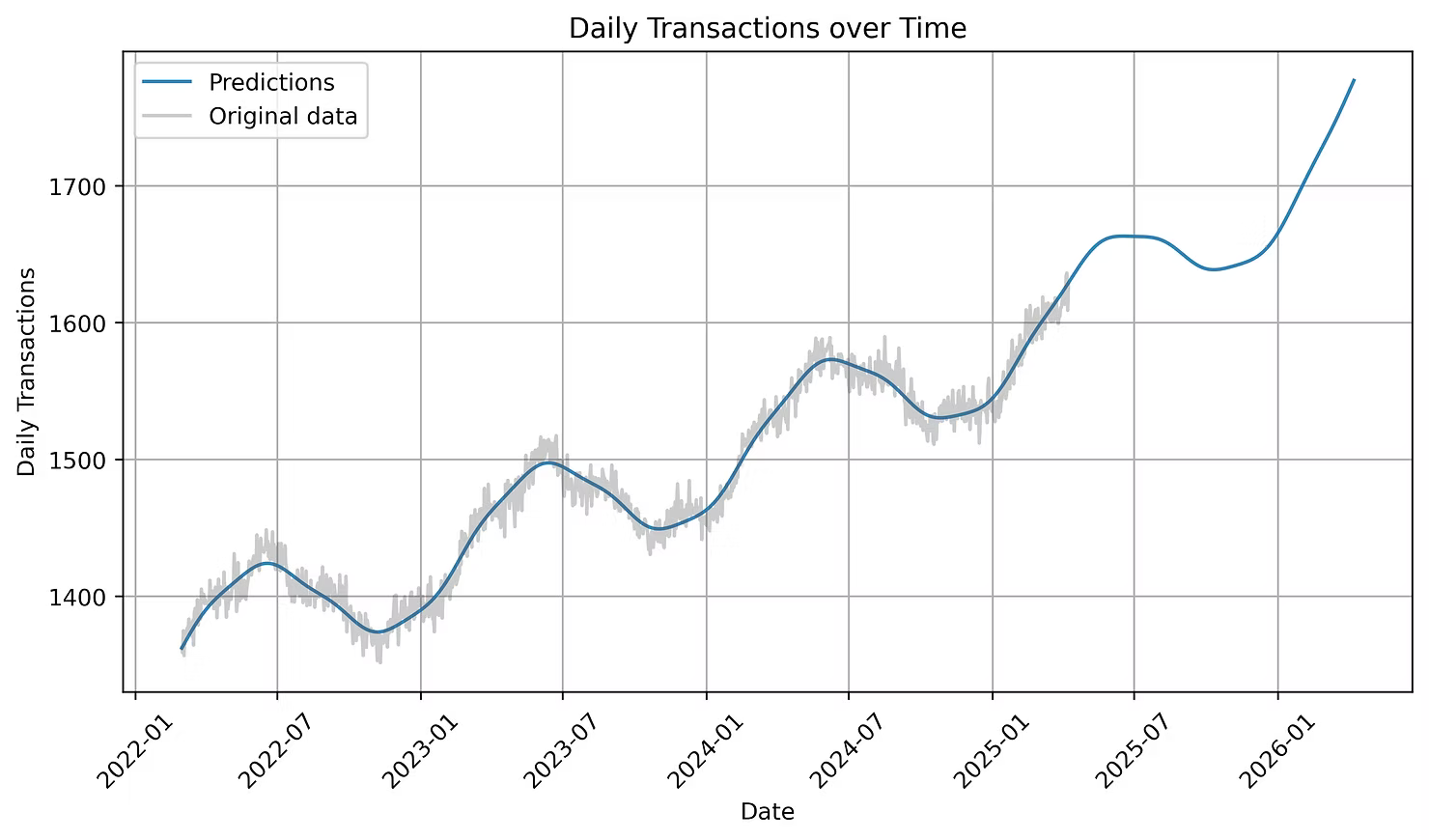
- Healthcare: Forecasting the number of patients each month helps hospitals allocate resources efficiently. By analyzing historical patient data, healthcare providers can anticipate future demand and ensure adequate staffing and supplies. Learn more about how predictive modeling enhances healthcare planning here.
- Statement of Work (SoW) generation: Estimating project timelines is crucial for effective project management. Regression models can analyze past project data to predict the duration of future projects, allowing for better planning and resource allocation. For a deeper dive into how we improve project estimation, check out our detailed guide here.
Mathematical foundation: Least squares, gradient descent
The mathematical foundation of regression involves techniques like least squares and gradient descent. Least squares minimizes the sum of squared differences between predicted and actual values, finding the best-fit line. Gradient descent is an optimization algorithm used to iteratively improve the model's parameters, ensuring accurate predictions. These mathematical principles provide the backbone for effective regression analysis.
Classification: Categorizing data
What is classification? Definition and purpose
Classification is a machine learning technique used to categorize data into predefined classes or labels. Unlike regression, which predicts continuous values, classification predicts discrete categories. For example, it can be used to determine whether an email is spam or not spam.
Types of classification: Binary vs. multi-class
Classification problems can be categorized into binary and multi-class. Binary classification involves two classes, such as "spam" or "not spam." Multi-class classification involves more than two classes, such as categorizing images of different animals. These variations allow for the application of classification in diverse scenarios.
Use cases:
- Spam detection and image recognition are common applications of classification. Spam filters use classification to identify unwanted emails, while image recognition systems categorize images based on their content.
- Healthcare: Disease diagnosis is a critical application of classification. By analyzing patient data, machine learning models can identify whether a patient has a specific disease, such as diabetes. Discover how AI-driven classification improves medical diagnosis here.
- E-commerce: An e-commerce platform might use data such as customer demographics, browsing behavior, and past purchase history to predict the likelihood of a customer making a purchase. This helps businesses tailor marketing strategies, personalize recommendations, and optimize inventory. By accurately predicting customer behavior, companies can increase conversion rates and improve overall sales performance.
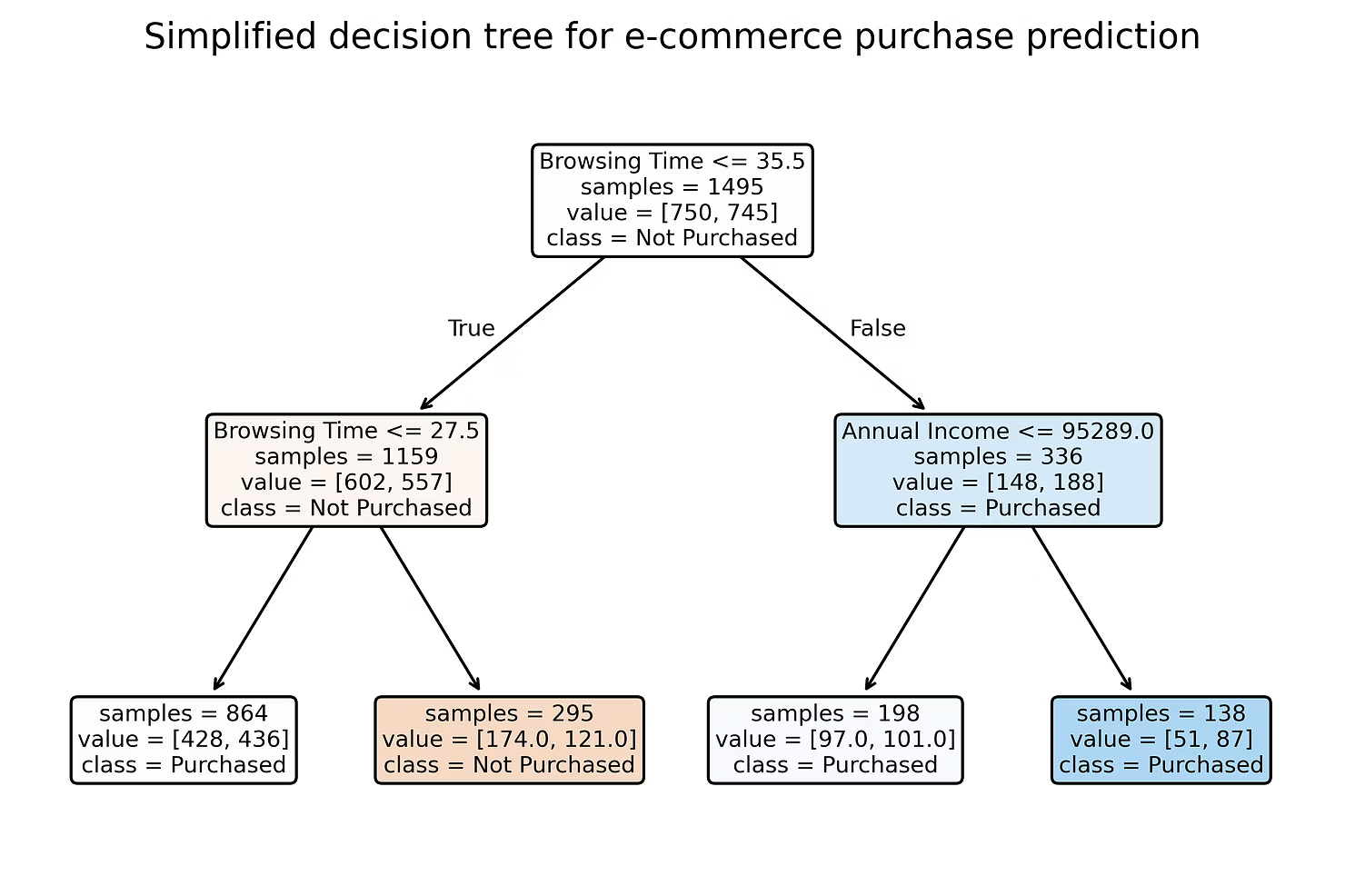
Algorithms: Neural networks, logistic regression, decision trees, random forests
Various algorithms are used for classification, including neural networks, logistic regression,
decision trees, and random forests. Neural networks are powerful models capable of capturing complex patterns. Logistic regression is a simpler model used for binary classification. Decision trees and random forests are ensemble methods that combine multiple decision trees for improved accuracy. These algorithms offer a range of options for different classification tasks.
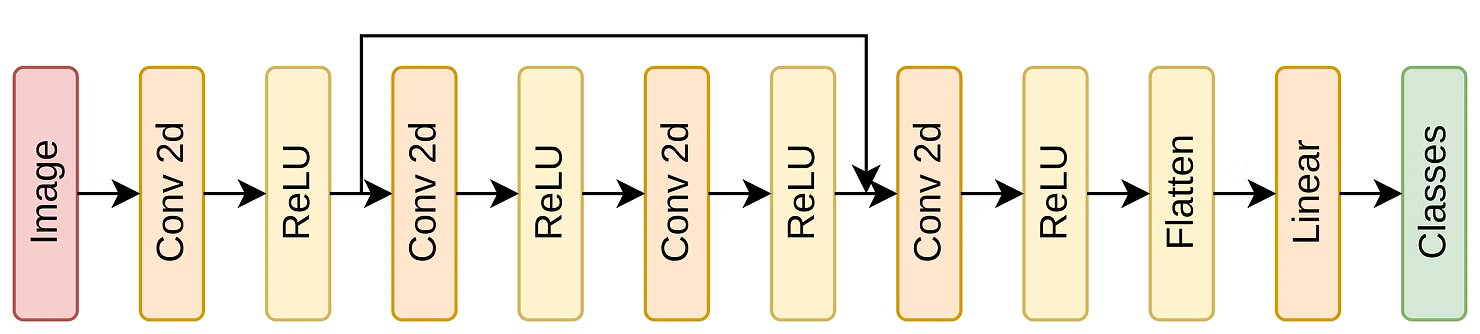
Clustering: Discovering hidden structures
What is clustering? Definition and purpose
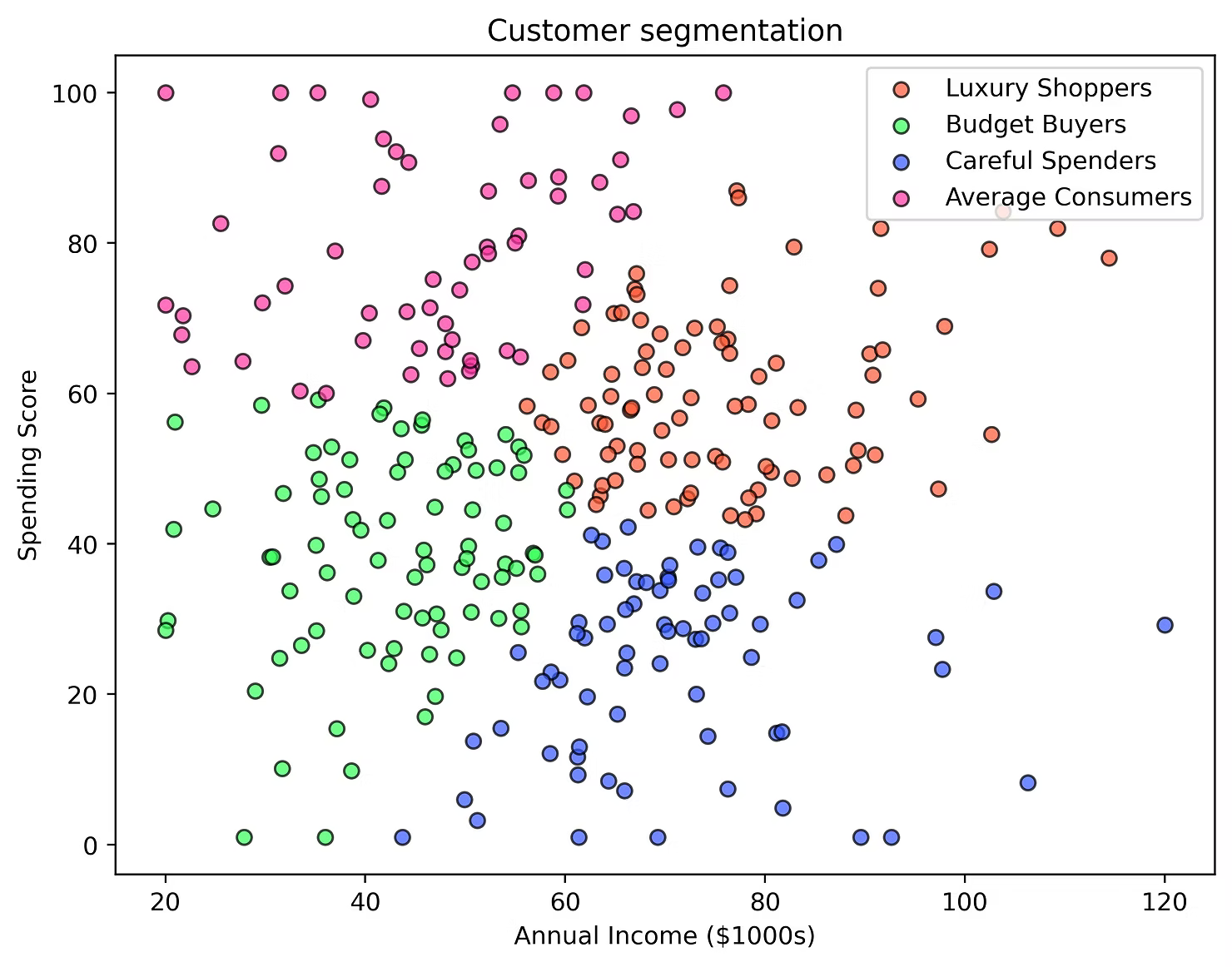
Clustering is an unsupervised learning technique used to group similar data points together. Unlike classification, which requires labeled data, clustering discovers hidden patterns in unlabeled data. For instance, it can be used to segment customers based on their purchasing behavior.
Types of clustering: K-means, hierarchical, DBSCAN
Clustering algorithms include K-means, hierarchical clustering, and DBSCAN. K-means partitions data into a predefined number of clusters. Hierarchical clustering builds a hierarchy of clusters. DBSCAN identifies clusters based on density. These algorithms offer different approaches to clustering, each suited for specific data characteristics.
Use cases:
- Customer segmentation and anomaly detection are common applications of clustering. Businesses use clustering to identify customer segments for targeted marketing, while anomaly detection identifies unusual patterns in data.
- Healthcare: Clustering plays a crucial role in patient segmentation, enabling more personalized treatment plans. By identifying groups of patients with similar characteristics, healthcare providers can optimize care strategies, improve patient outcomes, and enhance resource allocation planning. Learn more about its impact here.
| Technique | Strengths | Weaknesses |
|---|---|---|
| Regression | Predicts continuous values, models relationships between variables | Sensitive to outliers, assumes linear relationships |
| Classification | Categorizes data into predefined classes, handles discrete data | Requires labeled data, can be biased by imbalanced datasets |
| Clustering | Discovers hidden patterns in unlabeled data, groups similar data points | Sensitive to initial parameters, can be computationally intensive |
| Generative AI | Creates new content, generates realistic data | Requires large datasets, can produce biased or unrealistic outputs |
Note: Regardless of the chosen technique, it's crucial to remember that model performance can degrade over time. Regular retraining and validation are essential to maintain accuracy and reliability in real-world applications.
Conclusion: the power of AI techniques
Understanding the core AI techniques - regression, classification, clustering, and generative AI - is essential for leveraging AI in practical applications. These techniques offer diverse capabilities for analyzing data, predicting outcomes, and generating new content. As AI continues to evolve, these fundamental techniques will remain crucial for driving innovation and solving real-world problems.